Árvores Digitais usadas para Criação de Dicionários e Corretores Ortográficos (V7., N.10, P.6, 2024)
Tempo estimado de leitura: 9 minute(s)
Graças ao avanço da tecnologia em informática, a correção ortográfica se tornou uma parte essencial da comunicação no mundo digital. É por isso que hoje encontramos essa funcionalidade em praticamente todos os lugares, desde celulares simples e sistemas de busca até aplicativos de texto, sites e navegadores da Internet (Amorim & Zampieri, 2013). No entanto, implementar esses corretores não é tarefa fácil, especialmente devido à vasta quantidade de palavras em um idioma. Por isso, escolher a estrutura de dados certa é crucial para o sucesso da aplicação. As árvores digitais são uma dessas estruturas que têm uma ampla gama de aplicações na Ciência da Computação. Especificamente, elas são muito úteis para criar dicionários e corretores ortográficos eficientes (Bodon & Rónyai, 2003). Neste contexto, este artigo tem o objetivo de explicar brevemente o que é uma árvore digital, comentar sobre três importantes trabalhos da literatura, descrever sucintamente uma aplicação real que desenvolvemos, apresentar resultados de experimentos. Além disso, nas conclusões finais, serão citados possíveis caminhos futuros para o aprimoramento contínuo da aplicação desenvolvida.
O que é uma árvore digital?
A escolha da árvore digital é uma estratégia eficaz para organizar e buscar palavras em uma base de dados. Sua principal vantagem reside na organização hierárquica das palavras, o que resulta em uma redução significativa no número de comparações necessárias para encontrar a palavra desejada (Knut, 1973). Ao contrário de uma busca linear por cada palavra, onde o tempo de busca aumenta proporcionalmente com o número de palavras, a estrutura hierárquica da árvore digital permite uma busca mais rápida e eficiente. Cada nó na árvore representa um caractere na palavra, e os caminhos da raiz até as folhas representam as palavras completas (Bodon & Rónyai, 2003). Essa organização minimiza o número de comparações durante a busca, resultando em tempos de resposta mais rápidos. Na Figura 1 é possível visualizar um exemplo de árvore digital para as palavras “monte”, “mato”, “mano” e “gato”.
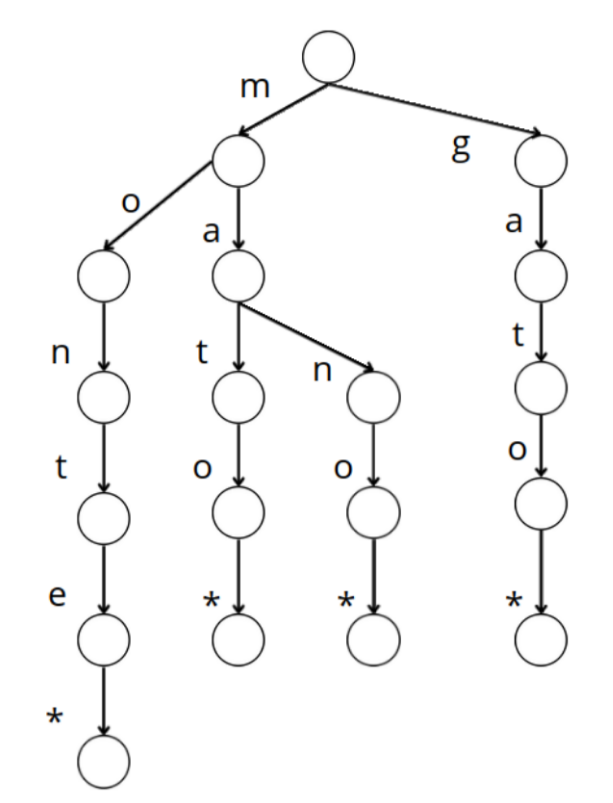
Figura 1: Exemplo de uma aplicação de árvore digital.
Vários estudos têm analisado como a árvore digital é útil para organizar grandes conjuntos de palavras em dicionários, tendo em vista que o tempo de busca não é influenciado pelo tamanho da base de dados, um ganho importante para encontrar palavras rapidamente. Ademais, o maior número de comparações feitas em uma busca é igual ao tamanho da maior palavra do dicionário.
Três importantes trabalhos da literatura
Karwowski e Wrzeciono (2017) comparam a árvore digital com outras estruturas de dados, como as árvores binárias de busca. A partir desse trabalho, vemos que cada uma delas tem suas vantagens em diferentes situações. Por exemplo, na comparação de palavras da língua polaca, os autores ressaltaram o grande uso de memória da árvore digital em comparação com a árvore binária de busca. Porém a árvore digital apresentou uma busca mais rápida.
Já o trabalho de Belém et al. (2022) apresenta formas de combinação de árvores digitais com a de busca binária. Essas formas visam essencialmente economizar memória quando procuramos palavras em textos longos. Esses estudos acabam preenchendo uma lacuna de pesquisa ao focar em como as árvores digitais podem funcionar quando temos de lidar com uma quantidade de dados que não cabe na memória principal.
Finalmente, visando um armazenamento de uma quantidade significativa de dados, a Doutora V. Suma (Suma, 2020) implementou o processamento de palavras em um serviço de nuvem, conjuntamente com a utilização de uma tabela hash auxiliar para aumentar a velocidade da busca. Esses três trabalhos constituem importantes exemplos de referências sobre o uso das estruturas de dados do tipo árvores digitais, bem como ressaltam como a pesquisa científica nesse tema tem sido desenvolvida.
Uma aplicação real para Árvores Digitais
A aplicação que desenvolvemos, ao receber uma palavra, não só fornece sua definição, mas também corrige a sua ortografia. Ademais, essa aplicação tem o desafio de trabalhar com um conjunto de dados suficientemente grande, a ponto de não caber completamente na memória principal ou secundária da máquina local.Nossa aplicação se constitui em uma API (Interface de Programação de Aplicação) com quatro módulos: dois dicionários, um em inglês e outro em espanhol, que fornecem definições para palavras fornecidas; e dois corretores, também nos idiomas inglês e espanhol. Quando uma palavra não está no dicionário consultado, os corretores fornecem possíveis ortografias corretas. Você pode encontrar mais detalhes e acesso ao código-fonte no repositório do GitHub (Braz & Melo, 2024).
Criamos bases de dados para inglês e espanhol, já que não encontramos recursos adequados online. Para lidar com grandes conjuntos de dados, dividimos os arquivos em partes menores e os armazenamos em contêineres no Azure Blob Storage, que é um serviço de armazenamento da plataforma de computação em nuvem da Microsoft. Devido ao tamanho dos arquivos, implementamos uma leitura parcial, em que cada busca por uma palavra envolve a leitura de um terço do arquivo por vez, simulando desta forma, o cenário onde a base não cabe na memória principal da máquina local.
Experimentos, Resultados e Análises
Para realizar os testes, criamos uma base constituída de uma seleção aleatória de palavras nos dois idiomas, inglês e espanhol, resultando em duas bases de 950 palavras cada, com comprimentos variando entre 1 e 19 caracteres. Este procedimento proporcionou uma visão abrangente do desempenho da busca para diferentes tamanhos de palavras.A avaliação dos resultados foi conduzida por meio do envio de requisição à API, com o intuito de analisar o desempenho da busca na árvore digital. Este procedimento permitiu aferir o tempo dedicado à busca na árvore. Ademais, realizamos o mesmo procedimento em Árvore AVL e na Árvore Rubro-Negra, que são árvores amplamente utilizadas por possuírem baixo tempo de busca. Desejávamos comparar a eficiência de busca nas três árvores.
Os resultados mostraram que, para ambos idiomas, a eficiência da busca se mostrou maior nas árvores digitais. Em específico, o tempo de busca nas árvores digitais cresce proporcionalmente com o tamanho da palavra. No caso das árvores AVL e Rubro-Negras, de forma geral, o tempo de busca é quase constante, tendo havido algumas poucas variações, provavelmente devido ao balanceamento das árvores e ao nível em que as chaves se localizavam na árvore.Ademais, destaca-se o impacto do tamanho da base no desempenho. A base de palavras em espanhol possui aproximadamente cinco vezes o tamanho da base em inglês. No entanto, como era esperado, a árvore digital não sofre alteração significativa no tempo médio de busca. Comparando os gráficos das Figuras 2 e 3, percebe-se que o tempo de busca não ultrapassa 5 microssegundos no caso das árvores digitais. Por outro lado, para as árvores AVL e Rubro-Negra, essa mudança é perceptível.
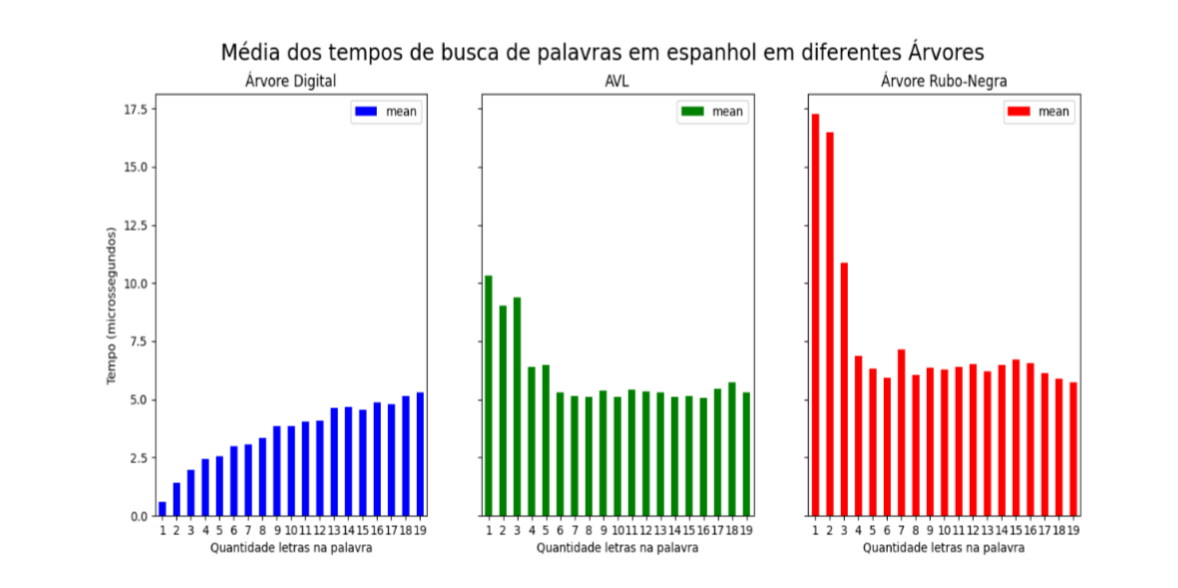
Figura 2: Média dos tempos de busca de palavras em espanhol em diferentes árvores.
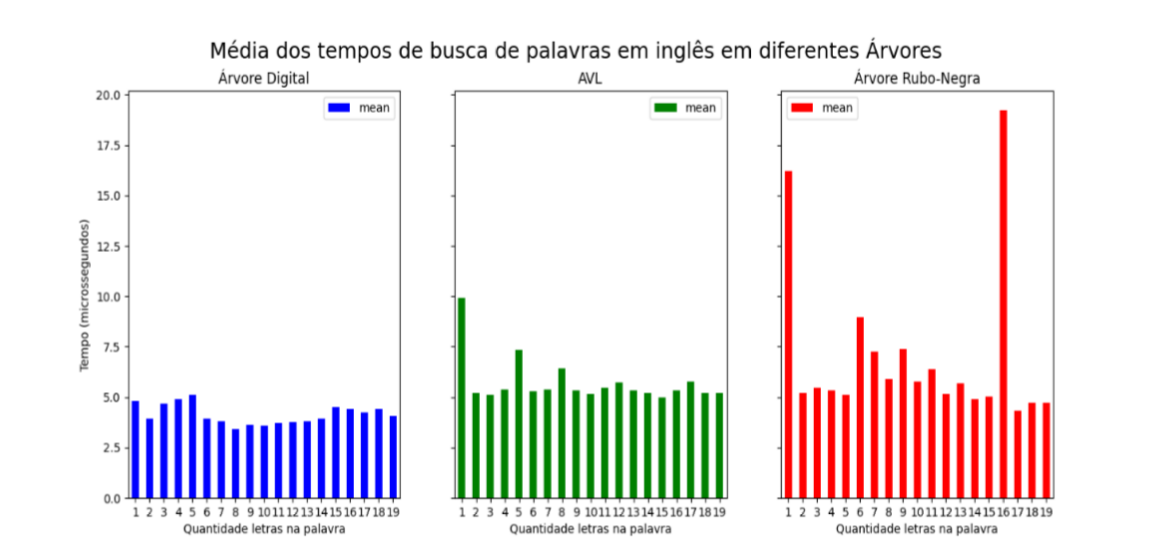
Figura 3: Média dos tempos de busca de palavras em inglês em diferentes árvores.
Conclusões finais
Concluindo, a análise comparativa entre a árvore digital e as estruturas AVL e Rubro-Negra revela que a árvore digital apresenta uma maior facilidade de implementação, bem como um desempenho igual ou superior em termos de tempo de busca. Dito isso, a árvore digital emerge como uma escolha mais vantajosa para a construção de dicionários e corretores ortográficos. Tendo em vista a aplicação desenvolvida e buscando aprimorar ainda mais a sua eficiência, algumas sugestões para futuros trabalhos incluem: 1) utilizar técnicas de processamento de linguagem natural, com fins de reduzir o conjunto de palavras a serem consultadas e os correspondentes tamanhos dessas palavras, o que contribuiria significativamente para a performance da aplicação (Karwowski & Wrzeciono, 2017); 2) explorar a combinação de diferentes árvores para extrair o melhor do que cada uma pode oferecer (Belém et al. 2022). Caso deseje conhecer maiores detalhes sobre nosso projeto e sua implementação, acesse: https://github.com/guilhermegbraz/Dicionario-ingles-espanhol-AEDII.
Referências
Amorim, R. C. and Zampieri, M. (2013). Effective spell checking methods using clustering algorithms. Proceedings of the International Conference Recent Advances in Natural Language Processing.
Braz, G. G. e Melo, I. (2024) F. Dicionário Inglês Espanhol GitHub. Disponível em: <https://github.com/guilhermegbraz/Dicionario-ingles-espanhol-AEDII> Acesso em: 2 mar. 2024.
Belém, R. J. S. et al. (2022). Combinando busca binária exata e busca aproximada em sistemas de complementação automática de consultas. Universidade Federal do Amazonas.
Bodon, F. and Rónyai, L. (2003). Trie: an alternative data structure for data mining algorithms. Volume 3. Mathematical and Computer Modelling. Páginas 739-751.
Karwowski, W. and Wrzeciono, P. (2017). The dictionary structure for effective word search. Information Systems in Management, Volume 6.
Knut, D. E. (1973). The art of computer programming. Sorting and searching. Volume 3. Addison-Wesley, Reading, MA, USA.
Suma, D. V. (2020). A novel information retrieval system for distributed cloud using hybrid deep fuzzy hashing algorithm. Journal of Information Technology and Digital World.

