
Selecionando DLTs para Aplicações Computacionais (V.8, N.7, P.6, 2025)
Estimated reading time: 32 minute(s)
Selecionando DLTs para Aplicações Computacionais
Em 2008, a proposta da criptomoeda Bitcoin sustentada pela Blockchain se tornou um marco para o desenvolvimento de aplicações computacionais de bancos de dados distribuídos. Desde então, vêm-se desenvolvendo diferentes categorias das denominadas tecnologias de registros distribuídos (DLTs – Distributed Ledger Technologies) para inúmeras áreas de negócio, muito além das aplicações financeiras. Universidades, agências governamentais, bancos, hospitais e vários outros segmentos da sociedade têm investindo nessas tecnologias para atingir maior efetividade em suas atividades.
Neste contexto, a seleção da categoria de DLTs mais adequada para uma dada aplicação computacional se torna um desafio. No processo de seleção, é necessário considerar as necessidades técnicas e de negócio da aplicação em si, a fim de garantir os níveis adequados de eficiência, segurança, auditabilidade, transparência e escalabilidade. Para auxiliar esse processo de seleção, vem-se desenvolvendo uma série de metodologias a fim de selecionar a categoria de DLT que melhor se encaixa na necessidade existente.
Ante o exposto, neste artigo definimos o conceito de DLT, apresentamos as suas principais categorias, citamos os mais conhecidos algoritmos de consenso, e apresentamos o Método de Seleção Ágil (MAS), recentemente proposto na literatura científica. Por fim, apresentamos as conclusões finais e indicamos direcionamentos para trabalhos futuros.
O que é exatamente uma DLT?
A rigor, a DLT é uma tecnologia utilizada para construção de bases de dados distribuídas de aplicações computacionais. A operação dessas bases de dados é realizada por meio de um conjunto de nós processadores interligados, constituindo uma rede sob topologia peer-to-peer (P2P). Os nós processadores guardam réplicas físicas dos dados a serem armazenados. Doravante, para maior simplicidade de explicação, nos referimos aos dados apenas como registros. Uma plataforma computacional baseada em DLT possui uma série de propriedades fundamentais, sendo as principais descritas a seguir.
- Consenso distribuído: O consenso que valida os registros na base de dados é descentralizado, sem depender de uma única entidade confiável;
- Imutabilidade: Todos os registros são armazenados de forma permanente na base de dados;
- Rastreabilidade e não repúdio: Todo os registros precisam ser digitalmente assinados por uma chave pública. Juntando essa característica à imutabilidade, é impossível existir dúvidas quanto aos autores de qualquer registro na rede;
- Controle e transparência: Todos os registros executados podem ser verificados pelos participantes do sistema, a partir da consulta dos nós processadores detentores das réplicas locais.
Quais são as categorias existentes de DLT?
De forma geral, existem três categorias de DLTs: Blockchain, Directed Acyclic Graph (DAG) e AD HOC. Cada uma dessas categorias possui diversas subcategorias com suas particularidades. A seguir exploraremos as características mais importantes de cada uma dessas três categorias.
Em uma DLT Blockchain, os registros são armazenados em conjuntos, conhecidos como blocos, que por sua vez são interligados um ao outro por meio de um hash. Esse hash referencia o bloco inserido anteriormente, criando uma lista encadeada. Além disso, é extremamente complicado computacionalmente fazer uma alteração nos registros de forma a manter os correspondentes hashes válidos. Dessa forma, os registros armazenados na rede são virtualmente imutáveis, criando um histórico de quando e por quem foram armazenados.
Enquanto os registros da Blockchain são armazenados em uma lista encadeada, os registros da DLT DAG são armazenados em uma rede de nós interconectados sob a topologia de um grafo direcionado acíclico. As subcategorias da DLT DAG são definidas pelo modo como os registros são armazenados e de acordo com a forma final do grafo resultante. Cada registro inserido faz referência a outros já existentes na rede, permitindo diversas inserções em paralelo. Por causa disso, as DLTs dessa categoria se destacam pela sua escalabilidade, que é um dos maiores problemas da categoria Blockchain. Existem duas subcategorias de DAG: uma armazena os registros individualmente, assim que uma requisição é recebida, e a outra armazena os registros em blocos.
Diferente das duas categorias anteriores, a categoria AD HOC não possui uma definição formal. No geral, se enquadram nessa categoria todas as DLTs desenvolvidas especificamente para um único sistema. Por causa disso, ainda faltam estudos para propriamente analisar a aplicabilidade dessa categoria em situações diferentes daquelas para as quais foram desenvolvidas. Levando isso em consideração, por simplicidade de exposição, a categoria AD HOC não é novamente citada ao longo do restante desse artigo.
Para que serve um algoritmo de consenso?
O primeiro algoritmo de consenso já criado, Proof-of-Work (PoW), foi implementado para o sistema de criptomoeda Bitcoin. Nele, só é possível inserir blocos na rede quando os nós fornecem provas de que conseguiram resolver um complexo desafio criptográfico. Se todos os outros nós da rede confirmarem que a solução é válida, o bloco é então inserido com sucesso no banco de dados. Por causa desse processo, o PoW é classificado como um algoritmo de computação intensiva, exigindo uma quantidade de energia e poder computacional que cresce exponencialmente, conforme a rede ganha mais nós processadores. Outro problema é a latência do sistema. Por exemplo, com o Bitcoin, demora-se cerca de 10 minutos para gerar um único bloco de transações.
Buscando solucionar os problemas descritos anteriormente, foram desenvolvidos outros algoritmos de consenso ao longo dos anos. Eles podem ser classificados nas três grandes classes a seguir.
- Proof-of-X: são algoritmos em que, para que algum bloco seja inserido, é necessário que seja fornecido algum tipo de prova, seja ela baseada na disponibilidade de poder computacional ou de algum outro recurso. Esses algoritmos se destacam por sua segurança, com sua desvantagem sendo o alto gasto energético e o risco de surgir um monopólio de poucos nós que quase sempre são capazes de realizar inserções de registros. São utilizados para a categoria de DLT Blockchain.
- Vote-based: são algoritmos em que a seleção do nó é feita por um sistema de votação. Eles são resistentes a falhas ou ações maliciosas de nós da rede, além de possuir maior vazão e gastar menos energia para atingir o consenso, apesar de não serem tão seguros quanto os algoritmos da classe Proof-of-X. São utilizados para a categoria de DLT Blockchain.
- DAG: são os algoritmos voltados para aplicações da categoria de DLT DAG. Em destaque, permitem maior eficiência e escalabilidade para as aplicações, comparativamente às duas classes anteriores. Cada subcategoria de DLT DAG, mencionada anteriormente, possui seus próprios algoritmos de consenso. Por serem algoritmos mais recentes, esses algoritmos ainda não estão em um estágio de desenvolvimento avançado.
Quais os métodos de seleção de DLT?
O método para seleção de uma DLT é fundamental para o desenvolvimento de um projeto computacional. Para o sucesso de uma aplicação, esse método deve considerar as limitações técnicas e os requisitos de negócio existentes. Com isso em mente, deve-se considerar requisitos tanto da equipe técnica de Tecnologia da Informação (TI) quanto da equipe de negócio.
Vários métodos de seleção já foram propostos na literatura, podendo ser classificados entre aqueles com etapas sequenciais, com divisão em estágios ou com mapeamento entre os levantamentos. Dentre esses métodos, os com mapeamento são os mais complexos, por estabelecerem uma interdependência entre as etapas. Naqueles divididos em estágios, é possível que o próximo estágio aproveite as informações do estágio anterior, tornando a análise final mais precisa.
Mesmo com a abundância de métodos disponíveis na literatura, grande parte deles não indicam qual categoria de DTL que é mais adequada ao projeto. Em vez disso, eles apontam apenas qual é a forma de participação mais adequada, ou seja, quais devem ser as políticas abordadas para que um usuário tenha acesso ao banco de dados. A exceção, até o momento, salvo melhor juízo, é o Método Ágil de Seleção (MAS), apresentado pelo trabalho de (Rodrigues, 2024). Além de indicar a forma de participação, esse método indica também o algoritmo de consenso que melhor se adequa ao projeto, juntamente com sua categoria de DLT correspondente.
Como é o Método Ágil de Seleção (MAS)?
O MAS possui, no total, dois estágios: o primeiro com quatro etapas e o segundo com outros dois. Cada etapa deve ser executada de forma sequencial, com as saídas do primeiro estágio servindo de entrada para o segundo, além das respostas da etapa anterior. Na Figura 1, são mostrados as etapas do MAS, bem como uma breve descrição de cada uma delas.
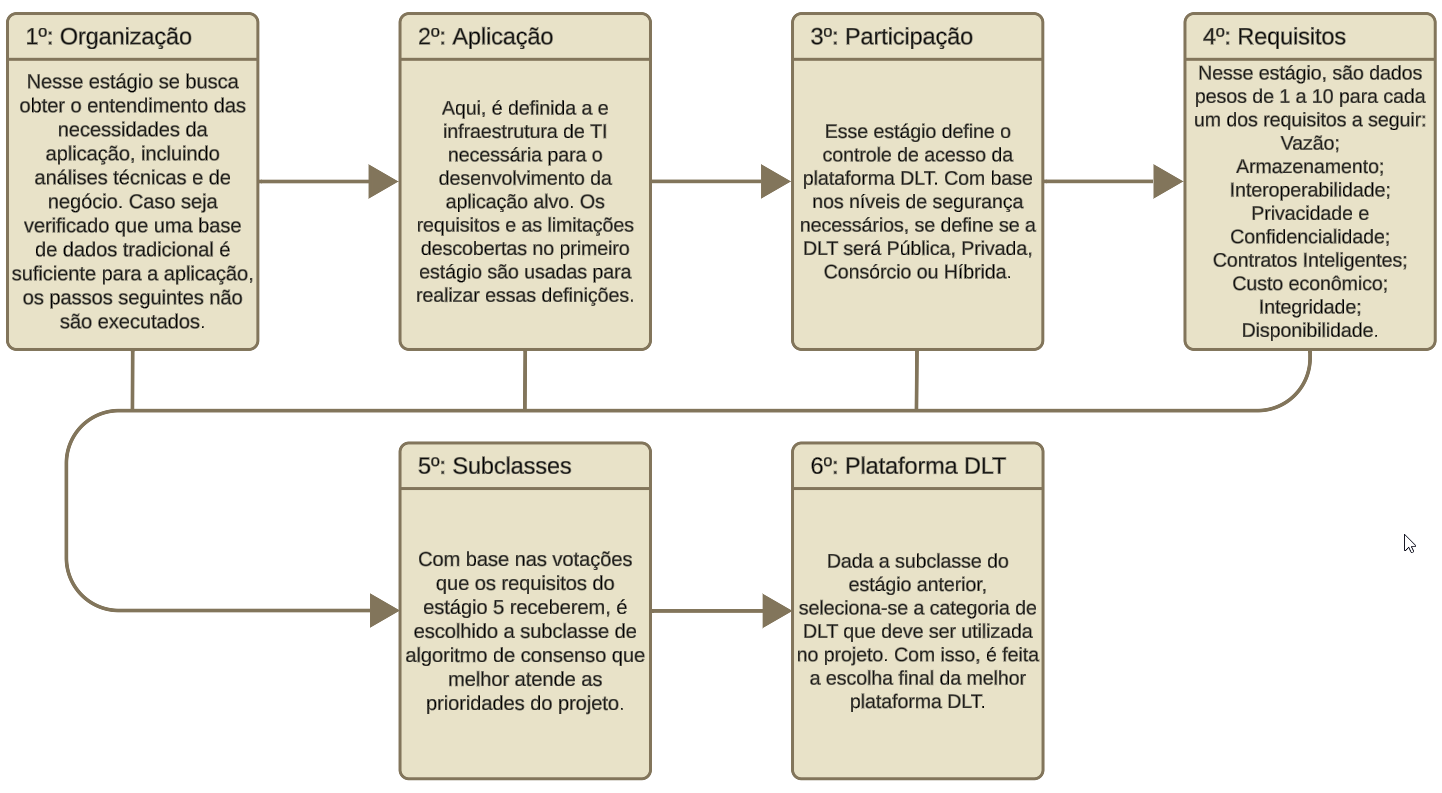
Ao realizar um estudo de caso, considerando uma visão simplificada do Sistema Único de Saúde (SUS) do Brasil, Rodrigues (2024) demonstra a eficiência e a simplicidade da aplicação do MAS no processo de seleção de uma DLT. Ao término dos seis estágios, foi recomendado o uso de uma DLT da categoria Blockchain, usando um algoritmo de consenso da classe Vote-based e com participação Privada.
Conclusões e o Futuro
A abundância de DLTs já desenvolvidas cria a necessidade de uma análise aprofundada e prévia dos requisitos de cada projeto. Isso para garantir a seleção correta da DLT. Para que esse processo decisório seja assertivo, é imprescindível o uso de metodologias adequadas. Como mostrado no trabalho de (Rodrigues, 2024), atualmente o MAS é a metodologia mais precisa para esse fim, pois recebe uma maior quantidade de dados de entrada, fornecendo assim uma sugestão mais completa do que outros métodos desenvolvidos anteriormente.
Mesmo assim, existem pontos que ainda faltam ser explorados. Trabalhos futuros podem focar em adicionar a categoria AD HOC a futuras metodologias, ampliando o leque de possíveis sugestões de saída (respostas). Além disso, a aplicação do MAS em outros estudos de caso e em casos reais será fundamental para permitir o refinamento do método no futuro.
Bibliografia
Dorothy G. Bundi, Stephen M. Mutua, Simon M. Karume. (2024). Underlying Consensus Algorithms, Architectures and Data Structures in Distributed Ledger Technologies Applications. Iconic Research and Engineering Journals Volume 7 Issue 7, 449-460. Disponível em: < https://www.irejournals.com/paper-details/1705448> Acesso em: 03 de março de 2025.
Fan, C., Ghaemi, S., Khazaei, H., & Musilek, P. (2020). Performance evaluation of blockchain systems: A systematic survey. IEEE Access, 8, 126927-126950. Disponível em: < https://doi.org/10.1016/j.eswa.2020.113385 >. Acesso em: 03 de março de 2025.
Rodrigues, C. K. da S. (2024). Bases de Dados Distribuídas para Aplicações Computacionais: Estudo e Seleção de Tecnologias de Registros Distribuídos. iSys-Brazilian Journal of Information Systems, 17(1), 12-1. Disponível em:< https://orcid.org/0000-0003-1231-6953 > Acesso em: 03 de março de 2025.
Seyed Mojtaba Hosseini Bamakan, Amirhossein Motavali, Alireza Babaei Bondarti. (2020). A survey of blockchain consensus algorithms performance evaluation criteria.
Expert Systems with Applications, Volume 154, 2020. Disponível em: < https://doi.org/10.1016/j.eswa.2020.113385> Acesso em: 03 de março de 2025.
Wang, Q., Yu, J., Chen, S., & Xiang, Y. (2023). SoK: DAG-based blockchain systems. ACM Computing Surveys, 55(12), 1-38. Disponível em: < https://dl.acm.org/doi/10.1145/3576899 > Acesso em: 03 de março de 2025.
Wu, H. Y., Yang, X., Yue, C., Paik, H. Y., & Kanhere, S. S. (2022). Chain or DAG? Underlying data structures, architectures, topologies and consensus in distributed ledger technology: A review, taxonomy and research issues. Journal of Systems Architecture, 131, 102720. Disponível em: < https://doi.org/10.1016/j.sysarc.2022.102720> Acesso em: 03 de março de 2025.