A importância da compressão de arquivos na Telemedicina (V.6. N.7. P.1, 2023)
Tempo estimado de leitura: 9 minute(s)
Desde o início do século, a telemedicina vem difundindo suas fronteiras para trazer serviços de saúde de centros desenvolvidos para localidades geograficamente distantes que não possuem atendimento médico especializado. Hoje em dia a maioria dos convênios extinguiu a carteirinha física e implantou abas de telemedicina em seus aplicativos. Além disso, já há a possibilidade de exames, consultas e até cirurgias serem feitas remotamente pelos médicos especialistas.
Para suportar esse emergente cenário tão avançado, são necessárias infraestruturas de redes de transmissão de dados para prover adequada comunicação entre médicos especialistas e setores hospitalares e/ou clínicas, os quais estão fisicamente separados entre si por dezenas ou centenas de quilômetros.
Contudo, apesar da ampla disponibilidade de conexão de rede de dados que temos hoje, os tamanhos dos arquivos a serem transmitidos ainda podem ser um grande obstáculo. É exatamente neste ponto em que entra a discussão da importância dos algoritmos de compressão. Neste artigo, vamos comentar sobre a Telemedicina, explicar brevemente o que é um algoritmo de compressão e, por fim, comparar e mostrar alguns resultados da aplicação de dois conhecidos algoritmos da literatura: Huffman e LZW.
O que é Telemedicina?
Podemos encontrar a seguinte definição na Wikipédia: “Telemedicina pode ser definida como o conjunto de tecnologias e aplicações que permitem a realização de ações médicas à distância. É possível que novas modalidades de ação médica, onde a telemedicina esteja sendo aplicada, surjam com grande velocidade nos próximos anos. Com a evolução dos meios de comunicação, é natural que o contato entre o médico e o paciente possa ser feito a distância. Por isso, ao contrário do que se possa pensar, todas as aplicações dessa técnica apresentaram respostas positivas, tanto de médicos quanto de pacientes.”
A partir dessa definição, vemos o grande potencial que temos para o desenvolvimento humano no tocante à sua saúde, que é o bem maior que um cidadão pode ter. Evolução científica e tecnológica sem saúde de nada adianta. Assim, estamos falando não só de desenvolvimento tecnológico e científico, mas também passamos a tratar concomitantemente de temas como inclusão social e democratização da assistência médica pública e universal.
O que é Compressão de Dados?
Para a área de estudo de Ciência da Computação, comprimir um arquivo de dados significa eliminar campos vazios, redundâncias, intervalos ou dados desnecessários. É como fazer o resumo de um artigo ou livro que se está estudando, pegam-se as partes primordiais para que o texto passe a mesma mensagem do original, porém retirando palavras ou frases que possam ser reduzidas a fim de economizar espaço.
Após a compressão, o arquivo de dados passa então a ter um menor tamanho medido em número bytes. Assim, a transmissão dos arquivos de dados se torna muito mais eficiente, pois se gasta menos tempo para transmitir a mesma informação. Além disso, a quantidade de memória necessária para se armazenar os arquivos de dados também é reduzida.
Porém, para realizar a compressão, é necessário mais do que um simples processo manual capaz de reescrever um texto, uma vez que aqui falamos de redução de tamanho de arquivos de dados sob o viés de processamento e armazenamento computacional. Para isso, temos os algoritmos computacionais, escritos em linguagens de programação, que desempenham o papel de operar uma série de comandos a fim de comprimir um arquivo de dados. A seguir analisaremos dois conhecidos algoritmos de compressão.
Algoritmos de Huffman e LZW
A codificação de Huffman surgiu em 1952, quando David Huffman inventou um algoritmo extremamente eficiente para o problema da árvore de Huffman de peso mínimo. A ideia consiste na análise da frequência de símbolos para que seja atribuído um código a cada um deles baseado na maior probabilidade de aparição na informação a ser transmitida. Ou seja, é um algoritmo baseado na probabilidade de ocorrência dos símbolos dos conjuntos de dados de forma a determinar códigos de tamanho variável para cada símbolo.
O algoritmo LZW (Lempel-Ziv-Welch) é um algoritmo de compressão de dados sem perda, amplamente utilizado para compactar informações. Ele foi desenvolvido por Abraham Lempel, Jacob Ziv e Terry Welch na década de 1980. A ideia geral por trás do algoritmo LZW é substituir sequências de caracteres repetidas por um código mais curto durante o processo de compressão.
Mais especificamente, o algorimo LZW percorre o texto buscando identificar padrões repetidos. À medida que encontra esses padrões repetidos, o algoritmo atribui códigos exclusivos a esses padrões e adiciona-os a um dicionário que vai sendo progressivamente criado. Durante a descompressão, este mesmo dicionário é então usado para reconstruir o texto original.
Uma comparação dos algoritmos na Telemedicina
A seguir comentamos brevemente sobre alguns resultados que obtivemos experimentalmente quando aplicamos os dois algoritmos em análise para arquivos de textos, imagens e vídeos da área da Telemedicina.
Conforme Figura 1, os arquivos de textos obtiveram as melhores taxas de compressão utilizando o algoritmo de LZW, além do tempo de compressão e descompressão ser também menor. Com os arquivos de imagem, conforme Figura 2, foi possível observar que, em 60% dos casos, o algoritmo LZW comportou-se melhor enquanto o Huffman. Finalmente, conforme Figura 3, para arquivos de vídeos, pudemos observar apenas razoáveis níveis de compressão. Enquanto Huffman obteve compressão 12,36% no melhor caso, LZW resultou em 15,81% no melhor caso. É bom ressaltar que esses níveis de compressão foram observados para arquivos típicos da Telemedicina. Ou seja, se os arquivos fossem de outra área de aplicação, como Engenharia ou Direito, os níveis observados de compressão poderiam ser completamente diferentes.
Como pudemos verificar, LZW obteve destaque em arquivos de texto e, também em arquivos de imagem. Isto porque LZW tem maior desempenho em imagens monocromáticas, que são a maioria dos casos em exames de imagem. Contudo, LZW não possui desempenho aceitável para aplicações com processamento em tempo real, como o caso dos vídeos. Logo, caso estejamos trabalhando com arquivos de texto e imagens monocromáticas, como Raio-X, é bem importante a utilização do LZW como algoritmo de compressão. Porém, caso a imagem não obedeça ao que foi relatado acima, melhor utilizar Huffman.
Caso queira dar uma olhadinha nas imagens e no código do projeto, sinta-se à vontade em visitar nosso GitLab. Lá você pode clonar o projeto pelo seguinte link: https://gitlab.com/cafezitopalito/lzw-and-huffman-for-telemedicine.
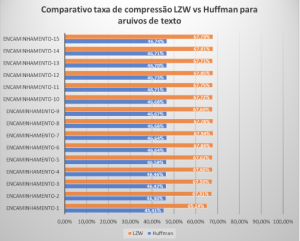
Figura 1: Compressão para arquivos de texto.
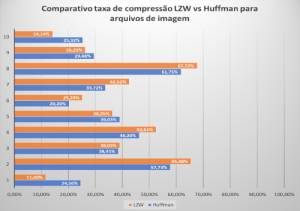
Figura 2: Compressão para arquivos de imagem.
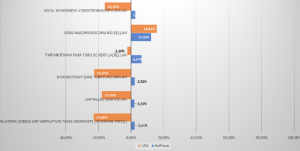
Figura 3: Compressão para arquivos de vídeo.


